今天遇到一現象,紀錄下來:
1. 10g table 新增3欄位
2. 9i 原本有此snapshot,故重新create snapshot
3. 9i 新的snapshot並沒有這3欄位
4. 將9i alter system flush shared_pool;
5. 9i 重新create snapshot,抓到這3欄位
2013年1月30日 星期三
9i 下sga_max_size 和SGA中各内存分配项的关系
http://space.itpub.net/35489/viewspace-84453
----------------------------------------------------------------
SGA_MAX_SIZE
Parameter type
Big integer
Syntax
SGA_MAX_SIZE = integer [K | M | G]
Default value
Initial size of SGA at startup, dependent on the sizes of different pools in the SGA, such as buffer cache, shared pool, large pool, and so on.
Parameter class
Static
Range of values
0 to operating system-dependent
----------------------------------------------------------------
sga_max_size 是 static 参数类型
一 直比较模糊的一个概念: SGA所包含的几个内存分配项( db buffer, share pool , large pool , java pool 等 ) 内存值发生变化导致整个SGA和发生变化时, sga_max_size 会不会自动变化 ( 根据定义应该是自动发生变化的,当startup时候 ) ?
产生这个疑问是源于看了一本performance tuning的书,上面写道:如果整个SGA内存区大小加和是 300 M , 而sga_max_size 被设置为 500m , 那么oracle仍然从空闲内存中要求 500 m 的内存 。也就是说Oracle 数据库启动时会向操作系统要求和sga_max_size 参数值相等的内存, 而不是去看SGA各项内存的加和 ( 这样可能造成浪费 ) 。
今天测试发现 sga_max_size 是随SGA中各内存分配项( db buffer, share pool , large pool , java pool 等 ) 的总和变化而变化的。当SGA各项变化导致总和发生变化, 那么sga_max_size 在重新启动db时就会自动根据变化的内存值总和改变自己的值 。
从上面分析可以得出,sga_max_size 其实是不需要手动调整的 ( 如果内存变更后允许startup的话 ) 。 应该不太可能出现上面提到的sga_max_size 被设置为 500m , 而SGA各项内存值加和才 300 m .
----------------------------------------------------------------
SGA_MAX_SIZE
Parameter type
Big integer
Syntax
SGA_MAX_SIZE = integer [K | M | G]
Default value
Initial size of SGA at startup, dependent on the sizes of different pools in the SGA, such as buffer cache, shared pool, large pool, and so on.
Parameter class
Static
Range of values
0 to operating system-dependent
----------------------------------------------------------------
sga_max_size 是 static 参数类型
一 直比较模糊的一个概念: SGA所包含的几个内存分配项( db buffer, share pool , large pool , java pool 等 ) 内存值发生变化导致整个SGA和发生变化时, sga_max_size 会不会自动变化 ( 根据定义应该是自动发生变化的,当startup时候 ) ?
产生这个疑问是源于看了一本performance tuning的书,上面写道:如果整个SGA内存区大小加和是 300 M , 而sga_max_size 被设置为 500m , 那么oracle仍然从空闲内存中要求 500 m 的内存 。也就是说Oracle 数据库启动时会向操作系统要求和sga_max_size 参数值相等的内存, 而不是去看SGA各项内存的加和 ( 这样可能造成浪费 ) 。
今天测试发现 sga_max_size 是随SGA中各内存分配项( db buffer, share pool , large pool , java pool 等 ) 的总和变化而变化的。当SGA各项变化导致总和发生变化, 那么sga_max_size 在重新启动db时就会自动根据变化的内存值总和改变自己的值 。
从上面分析可以得出,sga_max_size 其实是不需要手动调整的 ( 如果内存变更后允许startup的话 ) 。 应该不太可能出现上面提到的sga_max_size 被设置为 500m , 而SGA各项内存值加和才 300 m .
2013年1月29日 星期二
2013年1月28日 星期一
SAP : Auto convert SAP spool output to PDF file
http://www.erpgreat.com/bc037.htm
Auto convert SAP spool output to PDF file
As of Release 4.6D, PDF format (Adobe Acrobat data format) can be created via the SAP spooler by using the device type "PDF1".
As a workaround, a report (RSTXPDFT4) is made available for the missing "direct PDF printing", which can read spool requests, convert to PDF and perform a frontend download.
Read OSS Note 317851 - Printing PDF files in 4.6C/4.6B/4.5B
Note the restrictions specified in Note 323736 with the print output with PDF.
Caution when modifying device type ZPDF1, see Note 437696.
Version < 4.6D
If you are in version less than 4.6D, you can configure an output type to convert the spool automatically into a PDF format into your local harddisk but not do a "direct PDF printing".
When you print to this PDF output type, it will prompt you to enter the file name of your PDF file to be stored into your local harddisk.
First you have to add a printer using
Windows -> Start -> Settings -> Printers -> Generic / Text Only -> Port : Print to File
Next create a new device type e.g. ZPDF -> Select device type ZPDF1
Options for HostSpoolAccMethod -> Host spool access method : F : Printing on Frontend Computer
Host Printer : __DEFAULT or Generic / Text Only
Save your entries.
When you print to the device type ZPDF, choose Generic / Text Only for the Frontend Computer if it is not the default type.
A user prompt Print to File will appear to let you specify the Output File Name.
Auto convert SAP spool output to PDF file
As of Release 4.6D, PDF format (Adobe Acrobat data format) can be created via the SAP spooler by using the device type "PDF1".
As a workaround, a report (RSTXPDFT4) is made available for the missing "direct PDF printing", which can read spool requests, convert to PDF and perform a frontend download.
Read OSS Note 317851 - Printing PDF files in 4.6C/4.6B/4.5B
Note the restrictions specified in Note 323736 with the print output with PDF.
Caution when modifying device type ZPDF1, see Note 437696.
Version < 4.6D
If you are in version less than 4.6D, you can configure an output type to convert the spool automatically into a PDF format into your local harddisk but not do a "direct PDF printing".
When you print to this PDF output type, it will prompt you to enter the file name of your PDF file to be stored into your local harddisk.
First you have to add a printer using
Windows -> Start -> Settings -> Printers -> Generic / Text Only -> Port : Print to File
Next create a new device type e.g. ZPDF -> Select device type ZPDF1
Options for HostSpoolAccMethod -> Host spool access method : F : Printing on Frontend Computer
Host Printer : __DEFAULT or Generic / Text Only
Save your entries.
When you print to the device type ZPDF, choose Generic / Text Only for the Frontend Computer if it is not the default type.
A user prompt Print to File will appear to let you specify the Output File Name.
SAP : Configure SAP Printer to send spool as PDF attachment
http://sample-code-abap.blogspot.tw/2011/02/configure-sap-printer-to-send-spool-as.html
Configure SAP Printer to send spool as PDF attachment
This cool method will allow you to convert any SAP output in PDF format and send it as email attachment.
You must have used program RSTXPDFT4 earlier for similar purpose, however for normal user finding spool number and then executing program is too much. And I have seen users printing and scanning outputs to forward it to customer/vendor. This will simplify the whole process and provides an easy method to achieve the end result. Basically you define a printer in SAP with deriver type PDF and access method 'M'. And anything printed on this printer will be send as pdf attachment to email specified.
To define such printer follow below steps
1. Goto transaction SPAD (Spool Administrator) and Hit 'Display' button.

2. On next screen hit 'Create' button.

3. On 'Device Attributes' tab fill in 'Output device' and 'Short name'. Select device type 'PDF1 : PDF:ISO Latin-1 4.6D+'. Press F4 on Spool server and select relevant spool server from list.

4. On 'Access method' tab select 'M' as access method. Input 'Email address' and 'Only use This Mail Address' will appear. If you want all emails to be sent to one email address and would not allow user to change that email adderss then enter adddres and check the box. If left blank system will prompt user to enter email addrres before printing.

You must have used program RSTXPDFT4 earlier for similar purpose, however for normal user finding spool number and then executing program is too much. And I have seen users printing and scanning outputs to forward it to customer/vendor. This will simplify the whole process and provides an easy method to achieve the end result. Basically you define a printer in SAP with deriver type PDF and access method 'M'. And anything printed on this printer will be send as pdf attachment to email specified.
To define such printer follow below steps
1. Goto transaction SPAD (Spool Administrator) and Hit 'Display' button.
2. On next screen hit 'Create' button.
3. On 'Device Attributes' tab fill in 'Output device' and 'Short name'. Select device type 'PDF1 : PDF:ISO Latin-1 4.6D+'. Press F4 on Spool server and select relevant spool server from list.
4. On 'Access method' tab select 'M' as access method. Input 'Email address' and 'Only use This Mail Address' will appear. If you want all emails to be sent to one email address and would not allow user to change that email adderss then enter adddres and check the box. If left blank system will prompt user to enter email addrres before printing.
3 comments:

- AnonymousJuly 23, 2012 at 2:31 AMGood post, but need to mention some pre-requsites also.Reply
Please refer notes :
1.Note 311037 - Printing using e-mail
2.Note 513352 - Printing by e-mail (update)
3.Note 317851 - Creating PDF format using the SAP spooler in 4.6C-4.6B-4.5B.
Regards,
Sameersingh Pardeshi  Hi Sameersingh,Reply
Hi Sameersingh,Reply
Thanks for providing prerequisite for SAP R/3 4.6c.
However, this should work fine in ECC6.
Regards,
Pawan.

SAP : Easily Produce PDF Documents From Any SAP Reports
http://saphelpbykevin.knguyentu.com/2006/11/easily-produce-pdf-documents-from-any.html
There is a little known program available in SAP that will assist you in producing Adobe PDF output in most "standard" and "customized" SAP reports. The program is called "Converting SAPScript(OFT) or ABAP List Spool Job To PDF". You have to access it via transaction "SE38" or "SE80" using the program name "RSTXPDFT4".
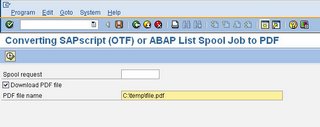 As
you can see from the screenshot above, this is a fairly simple program
to use. All you have to do is provide it a spool request ID.
As
you can see from the screenshot above, this is a fairly simple program
to use. All you have to do is provide it a spool request ID.
Example:
I will use the standard SAP delivered program "Entries and Leaves" (transaction: S_PH9_46000223 - EEs Entered and Left). Upon executing this transaction, I will get an ALV format output. Normally I would export this to MS Excel, however let say I would like to produce a PDF format instead.
From the menu bar, I would select List -> Print
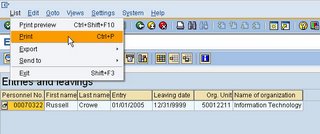
Upon printing, you will receive at the bottom of the screen a "Spool Request"

Using the spool request number, you would enter it into the program and execute. It is that simple!
There is a little known program available in SAP that will assist you in producing Adobe PDF output in most "standard" and "customized" SAP reports. The program is called "Converting SAPScript(OFT) or ABAP List Spool Job To PDF". You have to access it via transaction "SE38" or "SE80" using the program name "RSTXPDFT4".

Example:
I will use the standard SAP delivered program "Entries and Leaves" (transaction: S_PH9_46000223 - EEs Entered and Left). Upon executing this transaction, I will get an ALV format output. Normally I would export this to MS Excel, however let say I would like to produce a PDF format instead.
From the menu bar, I would select List -> Print

Upon printing, you will receive at the bottom of the screen a "Spool Request"

Using the spool request number, you would enter it into the program and execute. It is that simple!
SAP : Save Report Output to a PDF File
http://www.erpgenie.com/sap/abap/code/abap51.htm
This report takes another report as input, and captures the output of that report. The output is then converted to
PDF and saved to a local file. This shows how to use some of the PDF function modules, as well as an easy way to
create PDF files.
Source Code Listing
report zabap_2_pdf.
*-- Enhancements: only allow to be run with variant. Then called
*-- program will be transparent to users
*-- TABLES
tables:
tsp01.
*-- STRUCTURES
data:
mstr_print_parms like pri_params,
mc_valid(1) type c,
mi_bytecount type i,
mi_length type i,
mi_rqident like tsp01-rqident.
*-- INTERNAL TABLES
data:
mtab_pdf like tline occurs 0 with header line,
mc_filename like rlgrap-filename.
*-- SELECTION SCREEN
parameters:
p_repid like sy-repid, " Report to execute
p_linsz like sy-linsz default 132, " Line size
p_paart like sy-paart default 'X_65_132'. " Paper Format
start-of-selection.
concatenate 'c:\'
p_repid
'.pdf'
into mc_filename.
*-- Setup the Print Parmaters
call function 'GET_PRINT_PARAMETERS'
exporting
authority= space
copies = '1'
cover_page = space
data_set = space
department = space
destination = space
expiration = '1'
immediately = space
in_archive_parameters = space
in_parameters = space
layout = space
mode = space
new_list_id = 'X'
no_dialog= 'X'
user = sy-uname
importing
out_parameters = mstr_print_parms
valid = mc_valid
exceptions
archive_info_not_found = 1
invalid_print_params = 2
invalid_archive_params = 3
others = 4.
*-- Make sure that a printer destination has been set up
*-- If this is not done the PDF function module ABENDS
if mstr_print_parms-pdest = space.
mstr_print_parms-pdest = 'LOCL'.
endif.
*-- Explicitly set line width, and output format so that
*-- the PDF conversion comes out OK
mstr_print_parms-linsz = p_linsz.
mstr_print_parms-paart = p_paart.
submit (p_repid) to sap-spool without spool dynpro
spool parameters mstr_print_parms
via selection-screen
and return.
*-- Find out what the spool number is that was just created
perform get_spool_number using sy-repid
sy-uname
changing mi_rqident.
*-- Convert Spool to PDF
call function 'CONVERT_ABAPSPOOLJOB_2_PDF'
exporting
src_spoolid= mi_rqident
no_dialog = space
dst_device = mstr_print_parms-pdest
importing
pdf_bytecount = mi_bytecount
tables
pdf = mtab_pdf
exceptions
err_no_abap_spooljob = 1
err_no_spooljob = 2
err_no_permission = 3
err_conv_not_possible = 4
err_bad_destdevice = 5
user_cancelled = 6
err_spoolerror = 7
err_temseerror = 8
err_btcjob_open_failed = 9
err_btcjob_submit_failed = 10
err_btcjob_close_failed = 11
others = 12.
call function 'DOWNLOAD'
exporting
bin_filesize = mi_bytecount
filename = mc_filename
filetype = 'BIN'
importing
act_filename = mc_filename
tables
data_tab = mtab_pdf.
*---------------------------------------------------------------------*
* FORM get_spool_number *
*---------------------------------------------------------------------*
* Get the most recent spool created by user/report *
*---------------------------------------------------------------------*
* --> F_REPID *
* --> F_UNAME *
* --> F_RQIDENT *
*---------------------------------------------------------------------*
form get_spool_number using f_repid
f_uname
changing f_rqident.
data:
lc_rq2name like tsp01-rq2name.
concatenate f_repid+0(8)
f_uname+0(3)
into lc_rq2name separated by '_'.
select * from tsp01 where rq2name = lc_rq2name
order by rqcretime descending.
f_rqident = tsp01-rqident.
exit.
endselect.
if sy-subrc ne 0.
clear f_rqident.
endif.
endform." get_spool_number
SAP : Convert ABAP List to PDF and display in PDF format
http://an-sap-consultant.blogspot.tw/2010/12/sap-convert-abap-list-to-pdf-and.html
REPORT zrich_0001.
DATA: lv_spool LIKE tsp01-rqident.
DATA: lt_pdf TYPE TABLE OF tline.
DATA: ls_pdf LIKE LINE OF lt_pdf.
DATA: lv_url TYPE char255.
DATA: lv_buffer TYPE string.
DATA: lv_content TYPE xstring.
DATA: lt_data TYPE STANDARD TABLE OF x255.
DATA: lo_dialog_container TYPE REF TO cl_gui_dialogbox_container.
DATA: lo_docking_container TYPE REF TO cl_gui_docking_container.
DATA: lo_html TYPE REF TO cl_gui_html_viewer.
FIELD-SYMBOLS TYPE x.
PARAMETERS: p_check.
AT SELECTION-SCREEN OUTPUT.
* Run the report program, in this program you need to export the
* spool id to memory.
SUBMIT zrich_0002 TO SAP-SPOOL
WITHOUT SPOOL DYNPRO
DESTINATION space
COVER TEXT ' Your Report Title'
NEW LIST IDENTIFICATION 'X'
IMMEDIATELY space
AND RETURN.
* import spool number from memory
IMPORT lv_spool = lv_spool FROM MEMORY ID 'ZRICH_0002_SPONO'.
* Convert the spool request to PDF format.
CALL FUNCTION 'CONVERT_ABAPSPOOLJOB_2_PDF'
EXPORTING
src_spoolid = lv_spool
TABLES
pdf = lt_pdf
EXCEPTIONS
err_no_abap_spooljob = 1
err_no_spooljob = 2
err_no_permission = 3
err_conv_not_possible = 4
err_bad_destdevice = 5
user_cancelled = 6
err_spoolerror = 7
err_temseerror = 8
err_btcjob_open_failed = 9
err_btcjob_submit_failed = 10
err_btcjob_close_failed = 11
OTHERS = 12.
* convert pdf to xstring string
LOOP AT lt_pdf INTO ls_pdf.
ASSIGN ls_pdf TO CASTING.
CONCATENATE lv_content INTO lv_content IN BYTE MODE.
ENDLOOP.
CREATE OBJECT lo_docking_container
EXPORTING
repid = sy-repid
dynnr = sy-dynnr
side = lo_docking_container->dock_at_right
extension = 1200.
CREATE OBJECT lo_html
EXPORTING
parent = lo_docking_container.
* Convert xstring to binary table to pass to the LOAD_DATA method
CALL FUNCTION 'SCMS_XSTRING_TO_BINARY'
EXPORTING
buffer = lv_content
TABLES
binary_tab = lt_data.
* Load the HTML
lo_html->load_data(
EXPORTING
type = 'application'
subtype = 'pdf'
IMPORTING
assigned_url = lv_url
CHANGING
data_table = lt_data
EXCEPTIONS
dp_invalid_parameter = 1
dp_error_general = 2
cntl_error = 3
OTHERS = 4 ).
* Show it
lo_html->show_url( url = lv_url in_place = 'X' ).
REPORT zrich_0001.
DATA: lv_spool LIKE tsp01-rqident.
DATA: lt_pdf TYPE TABLE OF tline.
DATA: ls_pdf LIKE LINE OF lt_pdf.
DATA: lv_url TYPE char255.
DATA: lv_buffer TYPE string.
DATA: lv_content TYPE xstring.
DATA: lt_data TYPE STANDARD TABLE OF x255.
DATA: lo_dialog_container TYPE REF TO cl_gui_dialogbox_container.
DATA: lo_docking_container TYPE REF TO cl_gui_docking_container.
DATA: lo_html TYPE REF TO cl_gui_html_viewer.
FIELD-SYMBOLS TYPE x.
PARAMETERS: p_check.
AT SELECTION-SCREEN OUTPUT.
* Run the report program, in this program you need to export the
* spool id to memory.
SUBMIT zrich_0002 TO SAP-SPOOL
WITHOUT SPOOL DYNPRO
DESTINATION space
COVER TEXT ' Your Report Title'
NEW LIST IDENTIFICATION 'X'
IMMEDIATELY space
AND RETURN.
* import spool number from memory
IMPORT lv_spool = lv_spool FROM MEMORY ID 'ZRICH_0002_SPONO'.
* Convert the spool request to PDF format.
CALL FUNCTION 'CONVERT_ABAPSPOOLJOB_2_PDF'
EXPORTING
src_spoolid = lv_spool
TABLES
pdf = lt_pdf
EXCEPTIONS
err_no_abap_spooljob = 1
err_no_spooljob = 2
err_no_permission = 3
err_conv_not_possible = 4
err_bad_destdevice = 5
user_cancelled = 6
err_spoolerror = 7
err_temseerror = 8
err_btcjob_open_failed = 9
err_btcjob_submit_failed = 10
err_btcjob_close_failed = 11
OTHERS = 12.
* convert pdf to xstring string
LOOP AT lt_pdf INTO ls_pdf.
ASSIGN ls_pdf TO CASTING.
CONCATENATE lv_content INTO lv_content IN BYTE MODE.
ENDLOOP.
CREATE OBJECT lo_docking_container
EXPORTING
repid = sy-repid
dynnr = sy-dynnr
side = lo_docking_container->dock_at_right
extension = 1200.
CREATE OBJECT lo_html
EXPORTING
parent = lo_docking_container.
* Convert xstring to binary table to pass to the LOAD_DATA method
CALL FUNCTION 'SCMS_XSTRING_TO_BINARY'
EXPORTING
buffer = lv_content
TABLES
binary_tab = lt_data.
* Load the HTML
lo_html->load_data(
EXPORTING
type = 'application'
subtype = 'pdf'
IMPORTING
assigned_url = lv_url
CHANGING
data_table = lt_data
EXCEPTIONS
dp_invalid_parameter = 1
dp_error_general = 2
cntl_error = 3
OTHERS = 4 ).
* Show it
lo_html->show_url( url = lv_url in_place = 'X' ).
REPORT ZRICH_0002
line-count 65
LINE-SIZE 80.
DATA: lv_spool LIKE tsp01-rqident.
data: lv_value type i.
START-OF-SELECTION .
* Write the report.
DO 20 TIMES.
lv_value = sy-index * 10.
WRITE:/ sy-index, at 20 lv_value.
ENDDO.
* Export this spool number to memory
lv_spool = sy-spono.
EXPORT lv_spool = lv_spool TO MEMORY ID 'ZRICH_0002_SPONO'.
2013年1月22日 星期二
CIO的重要性與時間分配
http://www.gss.com.tw/index.php/eis/192
陳熙灝【叡揚資訊執行長 特助】
企業e化為企業拓展的關鍵已是不爭的事實,位居企業最高資訊主管CIO(Chief Information Officer)的重要性更不容忽視。雖有資訊長、資訊經理人或資訊策略副總裁等不同稱呼,就是企業最高資訊主管。CIO源自早期的資料處理處經理、資訊 管理處長、資訊副總,其角色雖有不同但其重要性卻有增無減。

由上圖CIO類型的分佈,我們可以看到CIO角色的轉變,未來功能首長CIO會大幅下降,而業務策劃長CIO會大幅增加。
.花最多時間與誰在一起?請見下圖說明。
 .管理與科技的排序何者最優先?業務策劃長的前十項分別為調整IT與營運目標;啟動IT流程的改善;創造營收的服務與產品;提高內部使用者的滿意度;營業的連續性與風險管理;IT員工的培養;IT成本的控管;改善案件管理的紀律;資料保密;衡量與傳遞IT價值。
.管理與科技的排序何者最優先?業務策劃長的前十項分別為調整IT與營運目標;啟動IT流程的改善;創造營收的服務與產品;提高內部使用者的滿意度;營業的連續性與風險管理;IT員工的培養;IT成本的控管;改善案件管理的紀律;資料保密;衡量與傳遞IT價值。
.想去創造最大影響的是什麼?業務策劃長的前十大領域分別為創造競爭優勢;推動商業革新;推動新的營收管道;提升外在客戶的滿意度;IT成本控管;使現在的營收成長;改善安全與風險管理;全球的擴展;供給線的自動化與透明化;宣導遵行規定。
.需要培養什麼技能?業務策畫長的八大核心管理技能分別為以客戶為關注焦點;改變領導風格;團隊領導關係;人力培養;協調合作與影響力;策略引導;市場知識;結果引導。
有36%(21%?0%)與非IT同事共事,著重於策略、商業過程執行與創新、發展新產品與服從;10%(4%?8%)與外在客戶/夥伴共事,進行銷售與 提供IT產品與服務。9%(5%?6%)督導IT工作。45%(32%?3%)提供公司範圍的IT服務與管理IT單位及廠商。而CIO為了實現四個角色的 時間配比,有賴於產業、IT管理的效能、IT組織的成熟度、外包的程度、各項度量的財務績效,以及CIO的類型。

陳熙灝【叡揚資訊執行長 特助】
企業e化為企業拓展的關鍵已是不爭的事實,位居企業最高資訊主管CIO(Chief Information Officer)的重要性更不容忽視。雖有資訊長、資訊經理人或資訊策略副總裁等不同稱呼,就是企業最高資訊主管。CIO源自早期的資料處理處經理、資訊 管理處長、資訊副總,其角色雖有不同但其重要性卻有增無減。
CIO要有資訊科技敏銳的嗅覺因人而異的溝通能力
今天CIO的角色已經不單是資訊部門的管理,其他像營收目標、IT外部網絡的管理,甚至HR、財務或資源分配等都要涉入。本身不僅要具備資訊科技與企業管 理的智能,對資訊科技的應用有敏銳的嗅覺,更要有因人而異的溝通能力,否則不但領導階層不買帳,連資訊科技人員都不諒解你。麻省理工學院斯隆管理學校 (Sloan School of management)資訊系統研究中心,自2007年3月起曾與全球規模達美金1.5B到70B公司的12位CIO面談,調查228位分散於26個國家 CIO及1353位IT首長之時間分配,並進行一系列的研究,在今年3月的研究報告「How CIO Allocate Their Time」對CIO有詳盡的分析,特摘錄部份精華於下。CIO需要更大的策略性與轉型力
依時間之分配將CIO歸類為三種類型:功能首長(Function Head)是以經營IT企業組織使其達到極佳的營運並提供可靠、有效率的服務為主;轉型領導人(Transformation Leader)是透過程序轉型以及商業上緊密夥伴關係為企業創造機會;業務策劃長(Business Strategists)是透過一些企業與面對外在客戶的活動,來推動具競爭優勢的策略。典型CIO的時間分配50%為功能首長,40%為轉型領導 人,10%為業務策劃長。而今年的調查則有了變化,分別為41%、49%、10%,因此可以看出在現今快速變化的年代,CIO需要更多的轉型領導。由上圖CIO類型的分佈,我們可以看到CIO角色的轉變,未來功能首長CIO會大幅下降,而業務策劃長CIO會大幅增加。
業務策劃長CIO的關鍵指標
既然未來CIO需要更具業務策劃的能力,業務策劃長CIO與其他CIO究竟有何不同,歸納為四個面向。.花最多時間與誰在一起?請見下圖說明。
.想去創造最大影響的是什麼?業務策劃長的前十大領域分別為創造競爭優勢;推動商業革新;推動新的營收管道;提升外在客戶的滿意度;IT成本控管;使現在的營收成長;改善安全與風險管理;全球的擴展;供給線的自動化與透明化;宣導遵行規定。
.需要培養什麼技能?業務策畫長的八大核心管理技能分別為以客戶為關注焦點;改變領導風格;團隊領導關係;人力培養;協調合作與影響力;策略引導;市場知識;結果引導。
CIO的時間分配模式
根據調查研究結果,CIO的時間分配模式如下圖所示:有36%(21%?0%)與非IT同事共事,著重於策略、商業過程執行與創新、發展新產品與服從;10%(4%?8%)與外在客戶/夥伴共事,進行銷售與 提供IT產品與服務。9%(5%?6%)督導IT工作。45%(32%?3%)提供公司範圍的IT服務與管理IT單位及廠商。而CIO為了實現四個角色的 時間配比,有賴於產業、IT管理的效能、IT組織的成熟度、外包的程度、各項度量的財務績效,以及CIO的類型。
您的時間分配是否反應了企業的需要呢?
該報告對於CIO也提出如下的建議步驟來運用時間分配模式分析您的時間分配是否反應了企業的需要:- 檢視您過去12個月的日記,將您的時間依照四個主要的CIO活動分配。
- 比較您的時間分配與圖上的平均相比較,並問以下的問題:我可以解釋自己目前的時間分配與155位CIOs的平均分配之間的差異嗎?那些最需要我注意的領域 (例如:建立IT管理,與銷售員交涉,教導IT員工,IT投資優先化,與外在客戶交涉,商業過程電子化央^是否反應在我的時間分配中?若是答案皆為 「是」,則您的時間分配看起來不錯。
- 若您在步驟二中的某些答案是「否」,則思考哪些地方是您可以做改變的,把花在較不重要工作的時間,集中於更重要的地方。
SAP MRP時間計算之四 : MRP date其它的決定因素
http://fredwang.blogspot.tw/search/label/SAP
有時您會發現,您根據上面三個單元算出的MRP date,仍與系統算出的不同,那麼請看下面的兩項因素:
1. Time fence(計劃時柵): 指定某時間內產生的planning orders不再被變更,因此若某planning order推算出的MRP date若落在time fence內則會自動將MRP date改至time fence結束日後。Time fence在物料主檔的MRP 1 view中維護。
2. Lot-sizing procedure(批量程序): 若採期間批量法,批量期間為週,則MRP date只會落在每週的第一個工作日,若某planning order推算出的MRP date落在一週的第三個工作日,則系統會將MRP date自動改至下一週的第一個工作日。批量期間為雙週(by-weekly),則MRP date只會落在每兩週的第一個工作日,批量期間為月,則MRP date只會落在每月的第一個工作日,依此類推。Lot sizing procedure在物料主檔的MRP 1 view中的批量欄維護。

有時您會發現,您根據上面三個單元算出的MRP date,仍與系統算出的不同,那麼請看下面的兩項因素:
1. Time fence(計劃時柵): 指定某時間內產生的planning orders不再被變更,因此若某planning order推算出的MRP date若落在time fence內則會自動將MRP date改至time fence結束日後。Time fence在物料主檔的MRP 1 view中維護。
2. Lot-sizing procedure(批量程序): 若採期間批量法,批量期間為週,則MRP date只會落在每週的第一個工作日,若某planning order推算出的MRP date落在一週的第三個工作日,則系統會將MRP date自動改至下一週的第一個工作日。批量期間為雙週(by-weekly),則MRP date只會落在每兩週的第一個工作日,批量期間為月,則MRP date只會落在每月的第一個工作日,依此類推。Lot sizing procedure在物料主檔的MRP 1 view中的批量欄維護。
直接在庫存/需求清單看主檔相關欄位

SAP MRP時間計算之三 : 廠內生產成品/半成品的MRP時間計算(以前置時間排程)
http://fredwang.blogspot.tw/search/label/SAP

說明:
1. 本計算方式適用於物料的採購類型為E(廠內生產)的料號。(請見物料主檔MRP 2 view) ,且執行MRP/MPS時使用的MRP控制參數 “排程” 為 2。
2. Lead time scheduling 計算方式與上一單元的差異在in-house production time的算法不同,本單元僅就此部份進行說明。
3. Float before production: 生產前至order start date的緩衝時間。在物料主檔的MRP 2 view中的排程臨界碼維護,排程臨界碼在Customizing中設定。
4. Float after production: 生產完成至order finsh date的緩衝時間。在物料主檔的MRP 2 view中的排程臨界碼維護,排程臨界碼在Customizing中設定。
5. Interoperation time(作業間時間): 包含Move time, Queue time, Wait time。以lead time scheduling 方式計算,廠內製造時間將會根據routing每一站的設定合計經每站所需的時間,含作業間時間及作業執行時間。
6. Queue time(佇列時間): 在Routing的作業明細內維護。
7. Wait time(等待時間): 物料移至下一站處理前的等待時間。在Routing的作業明細內維護。
8. Move time(運輸時間): 物料由本站移至下站所需的時間。在Routing的作業明細內維護。
9. Execution time(作業執行時間): 包含setup time, process time, teardown time。
10. Setup time(設立時間): 由Work center的排程頁面中設定的”設立公式”計算得到,該公式計算用參數可為Routing內的標準值或可設為固定常數。
11. Process time(處理時間): 由Work center的排程頁面中設定的”處理公式”計算得到,該公式計算用參數可為Routing內的標準值或可設為固定常數。
12. Teardown time(拆卸時間): 由Work center的排程頁面中設定的”拆卸公式”計算得到,該公式計算用參數可為Routing內的標準值或可設為固定常數。
13. Lead time scheduling可在routing的畫面中選 附加>排程>時程,進行模擬計算。

說明:
1. 本計算方式適用於物料的採購類型為E(廠內生產)的料號。(請見物料主檔MRP 2 view) ,且執行MRP/MPS時使用的MRP控制參數 “排程” 為 2。
2. Lead time scheduling 計算方式與上一單元的差異在in-house production time的算法不同,本單元僅就此部份進行說明。
3. Float before production: 生產前至order start date的緩衝時間。在物料主檔的MRP 2 view中的排程臨界碼維護,排程臨界碼在Customizing中設定。
4. Float after production: 生產完成至order finsh date的緩衝時間。在物料主檔的MRP 2 view中的排程臨界碼維護,排程臨界碼在Customizing中設定。
5. Interoperation time(作業間時間): 包含Move time, Queue time, Wait time。以lead time scheduling 方式計算,廠內製造時間將會根據routing每一站的設定合計經每站所需的時間,含作業間時間及作業執行時間。
6. Queue time(佇列時間): 在Routing的作業明細內維護。
7. Wait time(等待時間): 物料移至下一站處理前的等待時間。在Routing的作業明細內維護。
8. Move time(運輸時間): 物料由本站移至下站所需的時間。在Routing的作業明細內維護。
9. Execution time(作業執行時間): 包含setup time, process time, teardown time。
10. Setup time(設立時間): 由Work center的排程頁面中設定的”設立公式”計算得到,該公式計算用參數可為Routing內的標準值或可設為固定常數。
11. Process time(處理時間): 由Work center的排程頁面中設定的”處理公式”計算得到,該公式計算用參數可為Routing內的標準值或可設為固定常數。
12. Teardown time(拆卸時間): 由Work center的排程頁面中設定的”拆卸公式”計算得到,該公式計算用參數可為Routing內的標準值或可設為固定常數。
13. Lead time scheduling可在routing的畫面中選 附加>排程>時程,進行模擬計算。
SAP MRP時間計算之二 : 廠內生產成品/半成品的MRP時間計算(以基本日期)
http://fredwang.blogspot.tw/search/label/SAP

說明:
1. 本時間計算方式適用於物料的採購類型為E(廠內生產)的料號。(請見物料主檔MRP 2 view),且執行MRP時使用的MRP控制參數 “排程” 為 1。
2. Goods receipt processing time(收貨作業處理時間): 在物料主檔的MRP 2 view中維護。
3. In-house production time(廠內生產時間): 可以設定與批量相關或與批量無關兩種計算方式,若與批量無關則須在物料主檔的MRP 2 view中維護廠內生產日數,若與批量相關則須建立工作排程view,並在此view中維護setup time, processing time, interoperation time and base quantity
5. Release period: 決定production order應release的日期,與production order的維護有關,order release date = order start date – release period。在物料主檔的MRP 2 view中的排程臨界碼維護,排程臨界碼在Customizing中設定。
6. Backward scheduling: MRP類型屬於MRP或forecast-base planning(PD,VV)均採此方法計算。由物料的requirement date(MRP date)往前推算order start date,order finish date及plan opening date。

說明:
1. 本時間計算方式適用於物料的採購類型為E(廠內生產)的料號。(請見物料主檔MRP 2 view),且執行MRP時使用的MRP控制參數 “排程” 為 1。
2. Goods receipt processing time(收貨作業處理時間): 在物料主檔的MRP 2 view中維護。
3. In-house production time(廠內生產時間): 可以設定與批量相關或與批量無關兩種計算方式,若與批量無關則須在物料主檔的MRP 2 view中維護廠內生產日數,若與批量相關則須建立工作排程view,並在此view中維護setup time, processing time, interoperation time and base quantity
- Setup time(設置時間): 包含所有的設置(setup)及拆卸(teardown)時間。
- Processing time(加工處理時間)
- Interoperation time(加 工站間隔): 包含Move time, Queue time, Wait time, Float before production, Float after production, Planned delivery time of an operation processed externally等
- Base quantity(基礎數量)
- 批量相關的廠內生產時間 = setup time + interoperation time + (processing time * order quantity / base quantity )
- 注意:採”批量相關”計算時,請將MRP 2 view內的廠內生產日數設為零。
5. Release period: 決定production order應release的日期,與production order的維護有關,order release date = order start date – release period。在物料主檔的MRP 2 view中的排程臨界碼維護,排程臨界碼在Customizing中設定。
6. Backward scheduling: MRP類型屬於MRP或forecast-base planning(PD,VV)均採此方法計算。由物料的requirement date(MRP date)往前推算order start date,order finish date及plan opening date。
- Order finish date = MRP date - GR processing time
- Order start date = Order finish date – in-house production time
- Plan opening date = Order start date – opening period
- 若 計算出的order start date落在過去則系統自動切換成Forward scheduling 計算。(也可依廠別在Customizing設定即使order start date落在過去也不自動切換成forward scheduling, txn:OPPQ)
- Order finish date = Order start date + in-house production time
- MRP date = Order finish date + GR processing date
SAP MRP時間計算之一 : 外部採購物料的MRP時間計算
http://fredwang.blogspot.tw/search/label/SAP
原作時間 : 2000/4/7 作者: Fred F.M. Wang

說明:
1. 本時間計算方式適用於物料的採購類型為F(外部採購)的料號(請見物料主檔MRP 2 view)。
2. lead time offset(前 置期偏移 by 工作日): BOM上層組件(成品or半成品)的order start date的偏移值。正值表示該元件在製造開始後才有需要,負值表示該元件在製造前就應備好。因此元件的MRP date(requirement date) = 上層組件的order start date + lead time offset。在BOM元件項目的明細內維護。
3. Goods receipt processing time(收貨作業處理時間): 在物料主檔的採購view中維護。
4. Planned delivery time(計劃交貨時間): 若該物料有多家廠商,請設平均值。在物料主檔的MRP 2 view中維護。
5. Purchasing department processing time(採購處理時間): 採購文件所需的處理時間,依不同廠別在Customizing中設定(txn:OPPQ)。
6. Opening period: 為MRP controller將planned orders轉成PR or production orders的buffer time,例如,物管人員三天開一次PR則opening period應設為3(選排程臨界碼000)。在執行MRP前,將MRP控制參數”建立請購單”設為2(未確定期間的請購),執行後planning open date落在planning date及planning date前的planning orders會自動轉成PR,例如,4/6日run MRP則order start date在4/6未來三天的planning orders均會自動轉成PR。僅在Backward scheduling有用。在物料主檔的MRP 2 view中的排程臨界碼維護,排程臨界碼在Customizing中設定。
7. Backward scheduling: MRP類型屬於MRP或forecast-base planning(PD,VV)均採此方法計算。由物料的requirement date(MRP date)往前推算order release(start) date,order finish(delivery) date及plan opening date。(註: MRP類型請見物料主檔的MRP 1 View)
- Order finish(delivery) date = MRP date - GR processing time
- Order start(release) date = Order finish date – Planned delivery time – Processing time for purchasing
- Plan opening date = Order start date – opening period
8. Forward scheduling: MRP 類型屬於再訂購點方式(VB,VM)均採此方法計算或Backward scheduling計算時,order start date落在過去則系統自動會改成Forward scheduling 計算。以planning date為order release(start) date往後推算及order finish date及MRP date。
- Order finish(delivery) date = Order start date + Planned delivery time + Processing time for purchasing
- MRP date = Order finish date + GR processing time
SAP Phantom material(虛擬物料)觀念與設定
http://fredwang.blogspot.tw/search/label/SAP
有些半成品當一組成立即被父項用掉, 因此不會從現場領出(無庫存), 這類的半成品可列為Phantom material, 或某些元件之間在BOM中均集合列出, 可用一料號代表以方便管理, 此代表料號就是Phantom material.

上圖中, 半成品 "X"就是Phantom material
SAP 物料主檔的設定 :
在MRP 1 view中的special procurement欄位選50(Phantom assembly) lot size key 選擇"EX" (lot for lot)

有些半成品當一組成立即被父項用掉, 因此不會從現場領出(無庫存), 這類的半成品可列為Phantom material, 或某些元件之間在BOM中均集合列出, 可用一料號代表以方便管理, 此代表料號就是Phantom material.

上圖中, 半成品 "X"就是Phantom material
SAP 物料主檔的設定 :
在MRP 1 view中的special procurement欄位選50(Phantom assembly) lot size key 選擇"EX" (lot for lot)

如何簡化SAP的使用與開發,提升生產力
http://fredwang.blogspot.tw/search/label/SAP
簡化使用者操作1.使用SAP GuiXT簡化SAP標準畫面
2.使用者常用的Transaction可以單獨產生一個icon,減少操作;例如某個使用者主要工作是訂單輸入,則可以幫他為訂單輸入的Transaction產生一個icon,不用再經過選單動作
3.提供BI的環境,讓使用者快速產生自己需要的報表或匯出自己所需要的資料
4.開發客製化系統來包裝標準功能是最後的方法,可以簡化畫面的操作。客製化的系統可以在SAP內用ABAP開發或SAP外用Java,VB或Adobe Flex開發
簡化IT人員開發工作,提高生產力
1.善用ABAP Query的報表程式產生功能
2.善用SAP ALV技術-比傳統報表開發快速許多
3.善用Adobe PDF技術取代Smart Forms, SAP Script forms提高生產力
4.盡量SAP使用標準功能,進行Configuration or Enhancement
5.鼓勵並善用SAP庫存的Function Modules
6.除儘量使用SAP標準Function Modules外,鼓勵建立Function Modules並妥善管理與運用,鼓勵共用Function Modules以提高生產力(IT同仁養成建立並使用共用程式的習慣,建立重構refactoring的能力)
7.建立程式設計樣板,包含報表與Dialog Program的標準樣板,統一UI elements的設計樣式,減少人員系統設計的時間,並讓使用者有一致的操作體驗
8.(Optional)自行開發建立好用與強大的報表程式產生器,網路上也可以找到一些範例
9.提供BI的環境與訓練,讓使用者快速產生自己需要的報表或匯出自己所需要的資料,減少分析報表開發的時間
10.強化IT人員SAP開發工具的使用,包含Debugging tool, unit test tool, performance test tool, stress test tool..etc.
簡化使用者操作1.使用SAP GuiXT簡化SAP標準畫面
2.使用者常用的Transaction可以單獨產生一個icon,減少操作;例如某個使用者主要工作是訂單輸入,則可以幫他為訂單輸入的Transaction產生一個icon,不用再經過選單動作
3.提供BI的環境,讓使用者快速產生自己需要的報表或匯出自己所需要的資料
4.開發客製化系統來包裝標準功能是最後的方法,可以簡化畫面的操作。客製化的系統可以在SAP內用ABAP開發或SAP外用Java,VB或Adobe Flex開發
簡化IT人員開發工作,提高生產力
1.善用ABAP Query的報表程式產生功能
2.善用SAP ALV技術-比傳統報表開發快速許多
3.善用Adobe PDF技術取代Smart Forms, SAP Script forms提高生產力
4.盡量SAP使用標準功能,進行Configuration or Enhancement
5.鼓勵並善用SAP庫存的Function Modules
6.除儘量使用SAP標準Function Modules外,鼓勵建立Function Modules並妥善管理與運用,鼓勵共用Function Modules以提高生產力(IT同仁養成建立並使用共用程式的習慣,建立重構refactoring的能力)
7.建立程式設計樣板,包含報表與Dialog Program的標準樣板,統一UI elements的設計樣式,減少人員系統設計的時間,並讓使用者有一致的操作體驗
8.(Optional)自行開發建立好用與強大的報表程式產生器,網路上也可以找到一些範例
9.提供BI的環境與訓練,讓使用者快速產生自己需要的報表或匯出自己所需要的資料,減少分析報表開發的時間
10.強化IT人員SAP開發工具的使用,包含Debugging tool, unit test tool, performance test tool, stress test tool..etc.
SAP是甚麼的縮寫-Joke
SAP是甚麼的縮寫-Joke
Shutup and Pay
Send Another Payment
Stop All Processes
Suffer After Purchase
Slow and Painful
Slow And Problematic
Submit And Pray
Stress, Anxiety, Panic
Reference : "What does SAP stand for?" From http://www.experts-exchange.com
如同微軟, 最大的公司往往目標也最明顯, 最容易成為眾矢之的.
2013年1月18日 星期五
[Ubuntu]修復Grub2
http://jackzx01.pixnet.net/blog/post/31467908-%5Bubuntu%5D%E4%BF%AE%E5%BE%A9grub2
這幾天把新硬碟裝上並安裝M$的windows 7且我又剛好把USB硬碟插著,似乎將我的USB開機資訊給弄壞了~
害我USB硬碟的 Ubuntu 10.04 開機時候 猛重開機,逛了一堆GOOGLE文章還是這篇快又有效~一下子將損壞的開機資訊給修正了回來!
以下文章轉載自: 手把手玩Ubuntu http://playubuntu.blogspot.com/2010/07/ubuntu-grub2.html
Ubuntu 9.10,10.04都能使用此方法修複Grub開機選單,此方法應能適用大部份的狀況。剛好不知怎麼了,我的的開機選單出現錯誤,正好驗證一下寫的是否會有問題。
請準備一片與出問題的系統相符合或高於安裝版本的Ubuntu Live CD,因為,舊的可能無法辨別新版本所使用的分割格式,Live CD可以用複寫片燒錄就行,就算我能用硬碟直接安裝,還是會準備一片以便不時之需。
打開選單「系統」、「管理」、「磁碟工具程式」我系統安裝在/dev/sda(SATA 第一顆硬碟,編號從A開始,第二顆就是B囉),所以我要在sda找出掛載/的裝置,先把所需要的資料找出來。
▼把這些抄起來:1.裝置:/dev/sda 2.已掛載於:/ 3.分割區類型:ext4 4.掛載點/dev/sda5

插Ubuntu Live CD開機後,開啟終端機:
1、把原本系統的/掛載到到/mnt。
◎如果你/boot不是在/裡面,而是另外分割區,要先把/boot掛載到/mnt/boot在進行下一步。
2、安裝開機選單,我要裝到/dev/sda,root-directory為原來系統的/,安裝時/就指向/mnt。
1、把/dev/sda5的uuid找出來。
2、列出/mnt/boot目錄內容。
3、打開grub.cfg搜尋10_linux,比對內容是否相跟所查到的資料一樣。
▼1.找出uuid 2.列出boot內容 3.比對grub.cfg

註解:
因為我裝了3.0.0-30 後開不了機,所以應該是將/dev/sda1 的 /boot下面 所有 3.0.0-30 相關檔案移到另一目錄(或全部移除)後,再用以下指令
這幾天把新硬碟裝上並安裝M$的windows 7且我又剛好把USB硬碟插著,似乎將我的USB開機資訊給弄壞了~
害我USB硬碟的 Ubuntu 10.04 開機時候 猛重開機,逛了一堆GOOGLE文章還是這篇快又有效~一下子將損壞的開機資訊給修正了回來!
以下文章轉載自: 手把手玩Ubuntu http://playubuntu.blogspot.com/2010/07/ubuntu-grub2.html
Ubuntu 9.10,10.04都能使用此方法修複Grub開機選單,此方法應能適用大部份的狀況。剛好不知怎麼了,我的的開機選單出現錯誤,正好驗證一下寫的是否會有問題。
請準備一片與出問題的系統相符合或高於安裝版本的Ubuntu Live CD,因為,舊的可能無法辨別新版本所使用的分割格式,Live CD可以用複寫片燒錄就行,就算我能用硬碟直接安裝,還是會準備一片以便不時之需。
打開選單「系統」、「管理」、「磁碟工具程式」我系統安裝在/dev/sda(SATA 第一顆硬碟,編號從A開始,第二顆就是B囉),所以我要在sda找出掛載/的裝置,先把所需要的資料找出來。
▼把這些抄起來:1.裝置:/dev/sda 2.已掛載於:/ 3.分割區類型:ext4 4.掛載點/dev/sda5
實作修複Grub2開機選單
插Ubuntu Live CD開機後,開啟終端機:
1、把原本系統的/掛載到到/mnt。
sudo mount -t ext4 /dev/sda5 /mnt◎如果你/boot不是在/裡面,而是另外分割區,要先把/boot掛載到/mnt/boot在進行下一步。
2、安裝開機選單,我要裝到/dev/sda,root-directory為原來系統的/,安裝時/就指向/mnt。
sudo grub-install --root-directory=/mnt --recheck /dev/sda手動比對是否正確
1、把/dev/sda5的uuid找出來。
sudo blkid -s UUID -o value /dev/sda52、列出/mnt/boot目錄內容。
ls -l /mnt/boot3、打開grub.cfg搜尋10_linux,比對內容是否相跟所查到的資料一樣。
sudo gedit /mnt/boot/grub/grub.cfg▼1.找出uuid 2.列出boot內容 3.比對grub.cfg
註解:
因為我裝了3.0.0-30 後開不了機,所以應該是將/dev/sda1 的 /boot下面 所有 3.0.0-30 相關檔案移到另一目錄(或全部移除)後,再用以下指令
sudo grub-install --root-directory=/mnt --recheck /dev/sda 當然,重開機後,再將/etc/default/grub的預設選項想要改的再改回來即可
2013年1月17日 星期四
Oracle Waits - latch : cache buffer chains part 2
最近兩天發生此問題,一直往tuning方向去查。
最後發現不是如此,茲將歷史紀錄如下:
1. 新增兩個欄位,並開始補資料
2. 發現程式跑不出來,CPU utilization很高
3. v$session_wait 說:DB sequential read -> latch free -> 1) cache buffer chains ,2)也有enqueues
4. dbv沒有異常
5. analyze table ... validate structure -> ora-01410 ,invalid rowid
5. 最後判斷是DB block corruption造成,重建table
最後發現不是如此,茲將歷史紀錄如下:
1. 新增兩個欄位,並開始補資料
2. 發現程式跑不出來,CPU utilization很高
3. v$session_wait 說:DB sequential read -> latch free -> 1) cache buffer chains ,2)也有enqueues
4. dbv沒有異常
5. analyze table ... validate structure -> ora-01410 ,invalid rowid
5. 最後判斷是DB block corruption造成,重建table
刷新buffer cache
alter session set events 'immediate trace name flush_cache level 1';
alter system flush buffer_cache;
alter system flush buffer_cache;
Oracle Waits - latch : cache buffer chains
Oracle Waits - latch : cache buffer chains
Waits on the cache buffer chains latch, ie the wait event
"latch: cache buffers chains" happen when there is extremely high
and concurrent access to the same block in a database. Access to a block
is normally a fast operation but if concurrent users access a block
fast enough, repeatedly then simple access to the block can become an
bottleneck. The most common occurance of cbc (cache buffer chains) latch
contention happens when multiple users are running nest loop joins on a
table and accessing the table driven into via an index. Since the
NL join is basically a
For all rows in i
look up a value in j where j.field1 = i.val
end loop
then
table j's index on field1 will get hit for every row returned from i.
Now if the lookup on i returns a lot of rows and if multiple users are
running this same query then the index root block is going to get
hammered on the index j(field1).
In order to solve a
CBC latch bottleneck we need to know what SQL is causing the bottleneck
and what table or index that the SQL statement is using is causing the
bottleneck.
From ASH data this is fairly easy:
selectcount(*),sql_id,nvl(o.object_name,ash.current_obj#) objn,substr(o.object_type,0,10) otype,CURRENT_FILE# fn,CURRENT_BLOCK# blocknfrom v$active_session_history ash, all_objects owhere event like 'latch: cache buffers chains'and o.object_id (+)= ash.CURRENT_OBJ#group by sql_id, current_obj#, current_file#,current_block#, o.object_name,o.object_typeorder by count(*)/
From the out put it looks like we have both the SQL (at least the id, we can get the text with the id) and the block:
CNT SQL_ID OBJN OTYPE FN BLOCKN---- ------------- -------- ------ --- ------84 a09r4dwjpv01q MYDUAL TABLE 1 93170
But the block actually is probably left over from a recent IO and not actually the CBC hot block though it might be.
We
can investigate further to get more information by looking at P1, P2
and P3 for the CBC latch wait. How can we find out what P1, P2 and P3
mean? by looking them up in V$EVENT_NAME:
select * from v$event_namewhere name = 'latch: cache buffers chains'
EVENT# NAME PARAMETER1 PARAMETER2 PARAMETER3---------- ---------------------------- ---------- ---------- ----------58 latch: cache buffers chains address number tries
Now we can group the CBC latch waits by the address and find out what address had the most waits:
selectcount(*),lpad(replace(to_char(p1,'XXXXXXXXX'),' ','0'),16,0) laddrfrom v$active_session_historywhere event='latch: cache buffers chains'group by p1order by count(*);
COUNT(*) LADDR---------- ----------------4933 00000004D8108330
In
this case, there is only one address that we had waits for, so now we
can look up what blocks (headers actually) were at that address
select o.name, bh.dbarfil, bh.dbablk, bh.tchfrom x$bh bh, obj$ owhere tch > 5and hladdr='00000004D8108330'and o.obj#=bh.objorder by tch
NAME DBARFIL DBABLK TCH----------- ------- ------ ----EMP_CLUSTER 4 394 120
We
look for the block with the highest "TCH" or "touch count". Touch count
is a count of the times the block has been accesses. The count has
some restrictions. The count is only incremented once every 3 seconds,
so even if I access the block 1 million times a second, the count will
only go up once every 3 seconds. Also, and unfortunately, the count gets
zeroed out if the block cycles through the buffer cache, but probably
the most unfortunate is that this analysis only works when the problem
is currently happening. Once the problem is over then the blocks will
usually get pushed out of the buffer cache.
In the case where the CBC latch contention is happening right now we can run all of this analysis in one query
selectname, file#, dbablk, obj, tch, hladdrfrom x$bh bh, obj$ owhereo.obj#(+)=bh.obj andhladdr in(select ltrim(to_char(p1,'XXXXXXXXXX') )from v$active_session_historywhere event like 'latch: cache buffers chains'group by p1having count(*) > 5)and tch > 5order by tch
example output
NAME FILE# DBABLK OBJ TCH HLADDR------------- ----- ------ ------ --- --------BBW_INDEX 1 110997 66051 17 6BD91180IDL_UB1$ 1 54837 73 18 6BDB8A80VIEW$ 1 6885 63 20 6BD91180VIEW$ 1 6886 63 24 6BDB8A80DUAL 1 2082 258 32 6BDB8A80DUAL 1 2081 258 32 6BD91180MGMT_EMD_PING 3 26479 50312 272 6BDB8A80
This
can be misleading, as TCH gets set to 0 every rap around the LRU and it
only gets updated once every 3 seconds, so in this case DUAL was my
problem table not MGMT_EMD_PING
Deeper Analysis from Tanel Poder
Using Tanel's ideas here's a script to get the objects that we have the most cbc latch waits on
col object_name for a35col cnt for 99999SELECTcnt, object_name, object_type,file#, dbablk, obj, tch, hladdrFROM (select count(*) cnt, rfile, block from (SELECT /*+ ORDERED USE_NL(l.x$ksuprlat) */--l.laddr, u.laddr, u.laddrx, u.laddrr,dbms_utility.data_block_address_file(to_number(object,'XXXXXXXX')) rfile,dbms_utility.data_block_address_block(to_number(object,'XXXXXXXX')) blockFROM(SELECT /*+ NO_MERGE */ 1 FROM DUAL CONNECT BY LEVEL <= 100000) s,(SELECT ksuprlnm LNAME, ksuprsid sid, ksuprlat laddr,TO_CHAR(ksulawhy,'XXXXXXXXXXXXXXXX') objectFROM x$ksuprlat) l,(select indx, kslednam from x$ksled ) e,(SELECTindx, ksusesqh sqlhash, ksuseopc, ksusep1r laddrFROM x$ksuse) uWHERE LOWER(l.Lname) LIKE LOWER('%cache buffers chains%')AND u.laddr=l.laddrAND u.ksuseopc=e.indxAND e.kslednam like '%cache buffers chains%')group by rfile, block) objs,x$bh bh,dba_objects oWHEREbh.file#=objs.rfileand bh.dbablk=objs.blockand o.object_id=bh.objorder by cnt;
CNT OBJECT_NAME TYPE FILE# DBABLK OBJ TCH HLADDR---- ----------------- ----- ----- ------- ------ ----- --------1 WB_RETROPAY_EARNS TABLE 4 18427 52701 1129 335F7C001 WB_RETROPAY_EARNS TABLE 4 18194 52701 1130 335F7C003 PS_RETROPAY_RQST TABLE 4 13253 52689 1143 33656D003 PS_RETROPAY_RQST INDEX 4 13486 52692 997 33656D003 WB_JOB TABLE 4 14443 52698 338 335B90805 PS_RETROPAY_RQST TABLE 4 13020 52689 997 33656D005 WB_JOB TABLE 4 14676 52698 338 335B90805 WB_JOB TABLE 4 13856 52698 338 335F7C006 WB_JOB TABLE 4 13623 52698 338 335F7C007 WB_JOB TABLE 4 14909 52698 338 335B9080141 WB_JOB TABLE 4 15142 52698 338 335B90802513 WB_JOB INDEX 4 13719 52699 997 33656D00
Why do we get cache buffers chains latch contention?
In
order to understand why we get CBC latch contention we have to
understand what the CBC latch protects. The CBC latch protects
information controlling the buffer cache. Here is a schematic of
computer memory and the Oracle processes, SGA and the main components of
the SGA:

The
buffer cache holds in memory versions of datablocks for faster access.
Can you imagine though how we find a block we want in the buffer cache?
The buffer cache doesn't have a index of blocks it contains and we
certainly don't scan the whole cache looking for the block we want
(though I have heard that as a concern when people increase the size of
there buffer cache). The way we find a block in the buffer cache is by
taking the block's address, ie it's file and block number and hashing
it. What's hashing? A simple example of hashing is the "Modulo"
function
1 mod 4 = 12 mod 4 = 23 mod 4 = 34 mod 4 = 05 mod 4 = 16 mod 4 = 27 mod 4 = 38 mod 4 = 0
Using
"mod 4" as a hash funtion creates 4 possible results. These results are
used by Oracle as "buckets" or identifiers of locations to store
things. The things in this case will be block headers.

Block
headers are meta data about data block including pointers to the actual
datablock as well as pointers to the other headers in the same bucket.

The block headers in the hash buckets are connected via a doubly linked list. One link points forward the other points backwards

The resulting layout looks like

the steps to find a block in the cache are

If
there are a lot of sessions concurrently accessing the same buffer
header (or buffer headers in the same bucket) then the latch that
protects that bucket will get hot and users will have to wait getting
"latch: cache buffers chains" wait.

Two ways this can happen (among probably several others)

For
the nested loops example, Oracle will in some (most?) cases try and pin
the root block of the index because Oracle knows we will be using it
over and over. When a block is pinned we don't have to use the cbc
latch. There seem to be cases (some I think might be bugs) where the
root block doesn't get pinned. (I want to look into this more - let me
know if you have more info)
One
thing that can make CBC latch contention worse is if a session is
modifying the data block that users are reading because readers will
clone a block with uncommitted changes and roll back the changes in the
cloned block:

all these clone copies will go in the same bucket and be protected by the same latch:

selectcount(*), name, file#, dbablk, hladdrfrom x$bh bh, obj$ owhereo.obj#(+)=bh.obj andhladdr in(select ltrim(to_char(p1,'XXXXXXXXXX') )from v$active_session_historywhere event like 'latch: cache%'group by p1)group by name,file#, dbablk, hladdrhaving count(*) > 1order by count(*);
CNT NAME FILE# DBABLK HLADDR--- ---------- ------ ------- --------14 MYDUAL 1 93170 2C9F4B20
Notice
that the number of copies, 14, is higher the the max number of copies
allowed set by "_db_block_max_cr_dba = 6" in 10g. The reason is this
value is just a directive not a restriction. Oracle tries to limit the
number of copies.
Solutions
Find SQL ( Why is application hitting the block so hard? )
Possibly change application logicEliminate hot spots
Nested loops, possibly
Hash Partition the index with hot blockUse Hash Join instead of Nested loop joinUse Hash clusters
Look up tables (“select language from lang_table where ...”)
Change application
Use plsql function
Spread data out to reduce contention, like set PCTFREE to 0 and recreate the table so that there is only one row per block
Select from dual
Possibly use x$dualNote starting in 10g Oracle uses the "fast dual" table (ie x$dual) automatically when executing a query on dual as long as the column "dummy" is not accessed. Accessing dummy would be cases likeselect count(*) from dual;select * from dual;select dummy from dual;an example of not accessing "dummy" would be:select 1 from dual;select sysdate from dual;
Updates, inserts , select for update on blocks while reading those blocks
Cause multiple copies and make things worse
What would OEM do?




ORA-00603问题解决
alter system set events '10046 trace name context off';
alter system set timed_statistics=false;
結果下完後 出現 latch free -> cache buffer chains
alter system set timed_statistics=false;
結果下完後 出現 latch free -> cache buffer chains
2013年1月10日 星期四
Oracle : 存在則不回傳資料;不存在則回傳一筆資料
select ' ',' ',' '
from dwmgr.mes_Tbl_wo_status
where not exists (select null
from dwmgr.mes_Tbl_wo_status
where zvbeln = :vbeln and zposnr = :posnr
and txt04 in('REL','CRTD')
)
and rownum <= 1
from dwmgr.mes_Tbl_wo_status
where not exists (select null
from dwmgr.mes_Tbl_wo_status
where zvbeln = :vbeln and zposnr = :posnr
and txt04 in('REL','CRTD')
)
and rownum <= 1
2013年1月8日 星期二
如何下載YouTube影片
http://yeouching.com/?p=572
YouTube影片下載方式在網路上可以找到很多種,但是目前還是用Kej’s FLV Retriever網 站轉檔方法比較穩定。因為其它的下載方式,如國外網站所提供的快速下載方式,好像使用沒多久就失效了。另外有的就是要安裝一些程式才能下載。這種下載方式 不但所安裝的程式檔案很大,很佔電腦空間,要不然就是程式本身都很難操作。我覺得電腦內盡量不要安裝太多程式,才不會佔用電腦太多資源,影響到使用電腦的 流暢性。所以我還是選擇Kej’s FLV Retriever網站所提供的轉碼下載服務,不用安裝任何程式或軟體,就可以順利的把YouTube影片下載到我們自己的電腦內來觀賞。
YouTube所分享的影音檔案有分成幾種格式。解析度較小的是176X1443GP或 320X240 FLV等檔案,中型的640X360的MP4格式等檔案,還有就是高清、高畫質的1280X720的HD (720P)AVI檔案。但是要下載這些高畫質的影片,必需到YouTube專門下載的網址中才能取得。現在YouTube大多數的影音檔都有對應的FLV、MP4、3GP等格式,只有少部份才具有對應的720P高解析度版本。如果您只要單純的看到內容就可以,不用要求很高解析度影片的話,下載到FLV、MP4、3GP等格式的影音檔案,就可以滿足觀看的欲望了。
 第2步 再到轉碼網址http://kej.tw/flvretriever/轉碼︰
第2步 再到轉碼網址http://kej.tw/flvretriever/轉碼︰

第3步 出現另一個頁面的時候,點選〔步驟一︰請先下載此檔案〕。
 第4步 把「get_video_info」這個檔案儲存下來。(第3步的下載檔案,這個頁面不要關閉,等一下還要轉碼用。)
第4步 把「get_video_info」這個檔案儲存下來。(第3步的下載檔案,這個頁面不要關閉,等一下還要轉碼用。)
 第5步 「get_video_info」這個檔案沒有副檔名,您可以在「get_video_info」後面,自行加上去.txt。或者是點選此檔案之後,使用滑鼠右鍵功能表,選擇「開啟」。然後使用Notepad記事本,開啟此檔案。打開之後,把裡面長長的程式碼複製下來。
第5步 「get_video_info」這個檔案沒有副檔名,您可以在「get_video_info」後面,自行加上去.txt。或者是點選此檔案之後,使用滑鼠右鍵功能表,選擇「開啟」。然後使用Notepad記事本,開啟此檔案。打開之後,把裡面長長的程式碼複製下來。
 第6步 再回到第3步的轉碼網址http://kej.tw/flvretriever/剛剛下載檔案那個頁面上。
第6步 再回到第3步的轉碼網址http://kej.tw/flvretriever/剛剛下載檔案那個頁面上。
 第7步 如果您的電腦檔案,沒有顯示副檔名的話,可以在資料夾內設定。有顯示的話跳過這個步驟。打開電腦內的任何一個資料夾,在上方選按「工具」╱點選「資料夾選項」,會出現一個對話視窗。
第7步 如果您的電腦檔案,沒有顯示副檔名的話,可以在資料夾內設定。有顯示的話跳過這個步驟。打開電腦內的任何一個資料夾,在上方選按「工具」╱點選「資料夾選項」,會出現一個對話視窗。
 第8步 下載到的檔案,有的沒有副檔名,有
的是.htm或者是其他的副檔名。這裡要把沒有副檔名的,或者是和我們下載的影片格式,副檔名不同的,比如不是FLV的,改成該影音檔案的副檔名。在上面
第6步的圖解3,就可以很清楚的看到影片的副檔名。如︰Download(FLV, 640 x 360, Stereo 44KHz
AAC)這其中的FLV,就是這個影片檔的副檔名。
第8步 下載到的檔案,有的沒有副檔名,有
的是.htm或者是其他的副檔名。這裡要把沒有副檔名的,或者是和我們下載的影片格式,副檔名不同的,比如不是FLV的,改成該影音檔案的副檔名。在上面
第6步的圖解3,就可以很清楚的看到影片的副檔名。如︰Download(FLV, 640 x 360, Stereo 44KHz
AAC)這其中的FLV,就是這個影片檔的副檔名。
 第9步 已經下載完成的影片檔案,可以使用KMPlayer,這個超好用的影音播放軟體,來開啟影片觀賞。因為這個播放器,有支援FLV、MP4、3GP等等,萬用格式的影音檔案。
第9步 已經下載完成的影片檔案,可以使用KMPlayer,這個超好用的影音播放軟體,來開啟影片觀賞。因為這個播放器,有支援FLV、MP4、3GP等等,萬用格式的影音檔案。

YouTube影片下載方式在網路上可以找到很多種,但是目前還是用Kej’s FLV Retriever網 站轉檔方法比較穩定。因為其它的下載方式,如國外網站所提供的快速下載方式,好像使用沒多久就失效了。另外有的就是要安裝一些程式才能下載。這種下載方式 不但所安裝的程式檔案很大,很佔電腦空間,要不然就是程式本身都很難操作。我覺得電腦內盡量不要安裝太多程式,才不會佔用電腦太多資源,影響到使用電腦的 流暢性。所以我還是選擇Kej’s FLV Retriever網站所提供的轉碼下載服務,不用安裝任何程式或軟體,就可以順利的把YouTube影片下載到我們自己的電腦內來觀賞。
YouTube所分享的影音檔案有分成幾種格式。解析度較小的是176X1443GP或 320X240 FLV等檔案,中型的640X360的MP4格式等檔案,還有就是高清、高畫質的1280X720的HD (720P)AVI檔案。但是要下載這些高畫質的影片,必需到YouTube專門下載的網址中才能取得。現在YouTube大多數的影音檔都有對應的FLV、MP4、3GP等格式,只有少部份才具有對應的720P高解析度版本。如果您只要單純的看到內容就可以,不用要求很高解析度影片的話,下載到FLV、MP4、3GP等格式的影音檔案,就可以滿足觀看的欲望了。
網站名稱:Kej's FLV Retriever 網站網址:http://kej.tw/flvretriever/
如何下載YouTube的影片?
第1步 進入YouTube網站之後,在想下載的影片頁面中,把該網址列上的網址複製下來。- 把剛剛複製下來的網址,貼在文字欄位內。
- 按一下〔RETRIEVE NOW !〕按鈕。
第3步 出現另一個頁面的時候,點選〔步驟一︰請先下載此檔案〕。
- 把從記事本複製下來,長長的那一段程式碼,貼到文字區域內。
- 按一下〔送出〕,會出現一些如圖3的檔案格式及大小尺寸。
- 選擇要下載的檔案格式。一般都是下載FLV檔案格式。這裡可以使用瀏覽器來下載,也可以使用如快車等的續傳軟體下載。不過速度都差不多。
- 選擇「檢視」
- 取消勾選「隱藏已知檔案類型的副檔名」
- 按一下〔套用〕
2013年1月7日 星期一
oracle : create snapshot syntax
create materialized view sap_t435t
refresh complete WITH ROWID
start with sysdate
next sysdate+1
as
select * from dwmgr.sap_t435t@sap
refresh complete WITH ROWID
start with sysdate
next sysdate+1
as
select * from dwmgr.sap_t435t@sap
2013年1月3日 星期四
Reporting Service : Memory Configuration Settings
http://msdn.microsoft.com/en-us/library/ms159206.aspx
Configure Available Memory for Report Server Applications
...
Example of Memory Configuration Settings
The following example shows the configuration settings for a report server computer that uses custom memory configuration values. If you want to add WorkingSetMaximum or WorkingSetMinimum, you must type the elements and values in the RSReportServer.config file. Both values are integers that express kilobytes of RAM you are allocating to the server applications. The following example specifies that total memory allocation for the report server applications cannot exceed 4 gigabytes. If the default value for WorkingSetMinimum (60% of WorkingSetMaximum) is acceptable, you can omit it and specify just WorkingSetMaximum in the RSReportServer.config file. This example includes WorkingSetMinimum to show how it would appear if you wanted to add it:<MemorySafetyMargin>80</MemorySafetyMargin> <MemoryThreshold>90</MemoryThreshold> <WorkingSetMaximum>4000000</WorkingSetMaximum> <WorkingSetMinimum>2400000</WorkingSetMinimum>
About ASP.NET Memory Configuration Settings
Although
the Report Server Web service and Report Manager are ASP.NET
applications, neither application responds to memory configuration
settings that you specify in the processModel
section of machine.config for ASP.NET applications that run in IIS 5.0
compatibility mode. Reporting Services reads memory configuration
settings from the RSReportServer.config file only.
2013年1月2日 星期三
Reporting Service : pass null parameter value
http://server/ReportServer/Pages/ReportViewer.aspx?Report&Parameter:IsNull=True2013年1月1日 星期二
幾個重要 Operation 指標
幾個重要 Operation 指標
Quality : FPY report is ready @ MES
Cost : 1st stage 1-1-2 BOM cost report is ready @ SCMIP
2nd stage will be cost down trend chart by each parts
Delivery : 1st stage report is 齊料表 (under test)
2nd stage report will be L/T trend chart by each parts
Technology : 1st stage report is Lm/W vs LM/$ vs competitors trend by each product (request will be proposed)
Service : Field Dppm and Field Product Life are ready
Quality : FPY report is ready @ MES
Cost : 1st stage 1-1-2 BOM cost report is ready @ SCMIP
2nd stage will be cost down trend chart by each parts
Delivery : 1st stage report is 齊料表 (under test)
2nd stage report will be L/T trend chart by each parts
Technology : 1st stage report is Lm/W vs LM/$ vs competitors trend by each product (request will be proposed)
Service : Field Dppm and Field Product Life are ready
ruby : 二維array排序
升冪排序
tyruan@Ubuntu:~$
tyruan@Ubuntu:~$ ruby
a=[[1,3],[2,1],[3,5]]
b=a.sort_by{|x| x[1]}
puts "#{b}"
__END__
211335
降冪排序
a=[[1,3],[2,1],[3,5]]
b=a.sort {|x,y| y[1] <=> x[1]}
puts "#{b}"
[[3, 5], [1, 3], [2, 1]]
不知道降冪排序為何sort_by 沒有用,而sort可以???
tyruan@Ubuntu:~$
tyruan@Ubuntu:~$ ruby
a=[[1,3],[2,1],[3,5]]
b=a.sort_by{|x| x[1]}
puts "#{b}"
__END__
211335
降冪排序
a=[[1,3],[2,1],[3,5]]
b=a.sort {|x,y| y[1] <=> x[1]}
puts "#{b}"
[[3, 5], [1, 3], [2, 1]]
不知道降冪排序為何sort_by 沒有用,而sort可以???
ruby : Custom Firefox path
http://code.google.com/p/selenium/wiki/RubyBindings
Custom Firefox path
If your Firefox executable is in a non-standard location:Selenium::WebDriver::Firefox.path = "/path/to/firefox" driver = Selenium::WebDriver.for :firefox
訂閱:
意見 (Atom)
Thanks for the same.
Regards,
Ravi